Abstract
With the revolution of generative AI, video-related tasks have been widely studied. However, current state-of-the-art video models still lag behind image models in visual quality and user control over generated content. In this paper, we introduce TokenWarping, a novel framework for temporally coherent video translation. Existing diffusion-based video editing approaches rely solely on key and value patches in self-attention to ensure temporal consistency, often sacrificing the preservation of local and structural regions. Critically, these methods overlook the significance of the query patches in achieving accurate feature aggregation and temporal coherence. In contrast, TokenWarping leverages complementary token priors by constructing temporal correlations across different frames. Our method begins by extracting optical flows from source videos. During the denoising process of the diffusion model, these optical flows are used to warp the previous frame's query, key, and value patches, aligning them with the current frame's patches. By directly warping the query patches, we enhance feature aggregation in self-attention, while warping the key and value patches ensures temporal consistency across frames. This token warping imposes explicit constraints on the self-attention layer outputs, effectively ensuring temporally coherent translation. Our framework does not require any additional training or fine-tuning and can be seamlessly integrated with existing text-to-image editing methods. We conduct extensive experiments on various video translation tasks, demonstrating that TokenWarping surpasses state-of-the-art methods both qualitatively and quantitatively.
Overview
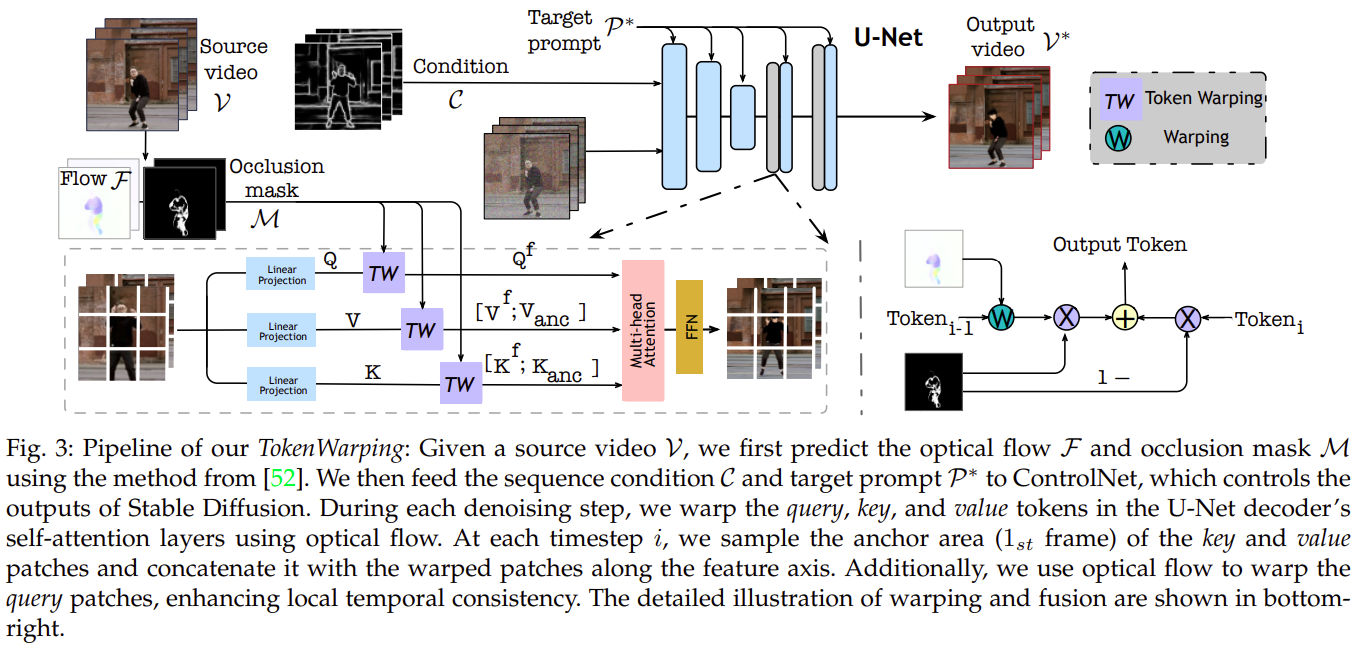
Longer Video Results
Optical Flow Results
Appearance Flow for Large Gap Editing
Comparison with State-of-the-Art Methods
Comparison Results with Inversion Code
Ablations
Challenging Cases
Citation
If you find our work helpful, please consider citing:
@article{article,
author = {Zhu, Haiming and Xu, Yangyang and Yu, Jun and He, Shengfeng},
year = {2025},
month = {11},
pages = {1-11},
title = {Zero-Shot Video Translation via Token Warping},
volume = {PP},
journal = {IEEE Transactions on Visualization and Computer Graphics},
doi = {10.1109/TVCG.2025.3636949}
}
}Acknowledgement
Most of our code is adapted from FRESCO and ControlVideo. We sincerely thank the authors for their great contributions.